
DataHive AI
AI • Data Analysis
Decentralized AI data collection platform
Janction is a decentralized, AI-native GPU resource sharing platform designed to power the next generation of verifiable and collaborative artificial intelligence. As the first Layer 2 infrastructure optimized for AI workloads, Janction combines blockchain architecture, smart contracts, and distributed computing to deliver scalable, efficient, and secure infrastructure for data-intensive machine learning tasks.
Through its decentralized GPU marketplace, Janction enables users to rent and lease GPU power, data storage, and prebuilt AI services across a peer-to-peer, transparent ecosystem. With features such as Proof of Contribution, workload verification, and containerized computing clusters, Janction empowers developers, enterprises, and researchers to efficiently run AI pipelines, reduce deployment costs, and unlock new forms of data monetization in a trustless environment.
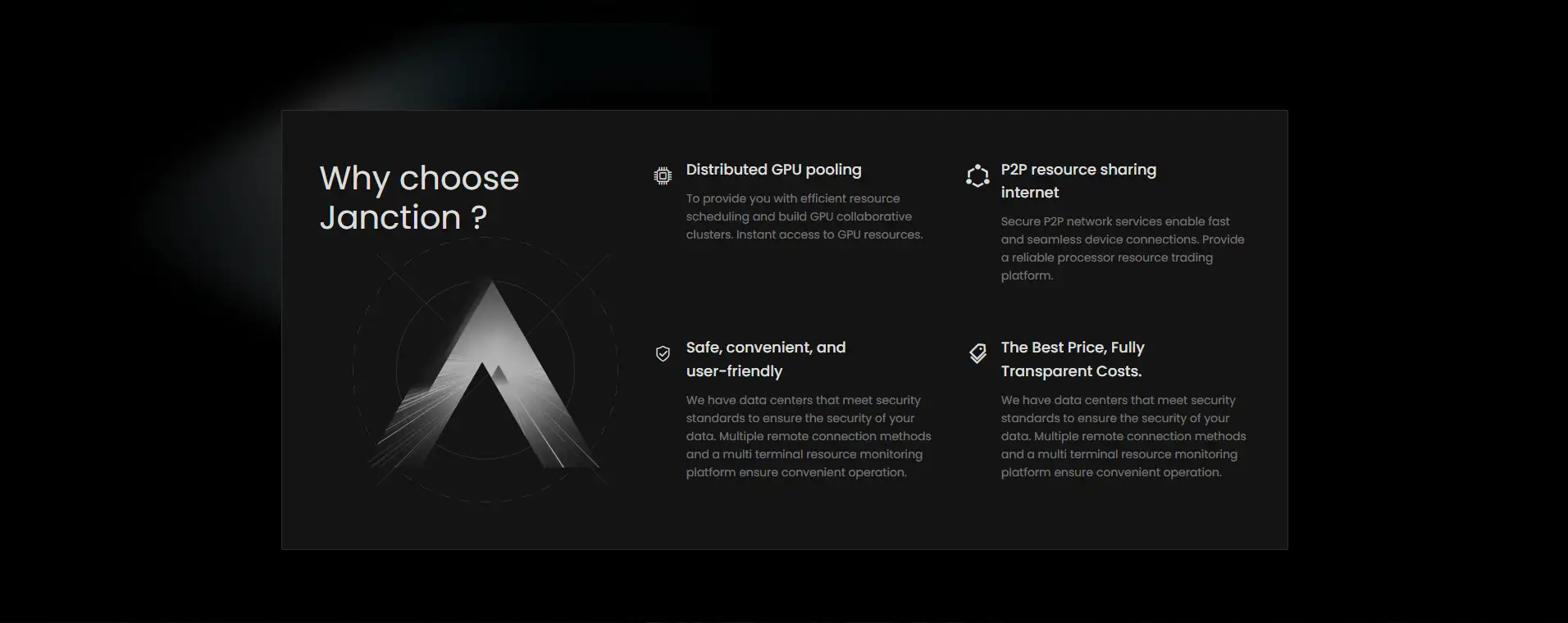
Janction is building the foundational infrastructure for decentralized artificial intelligence by merging distributed computing with blockchain-backed coordination. The platform serves as a powerful AI compute marketplace, where users can securely rent, contribute, and manage GPU power for machine learning workloads across sectors like image generation, object detection, speech recognition, and LLM hosting. The system is designed around resource interoperability, verifiability, and economic fairness.
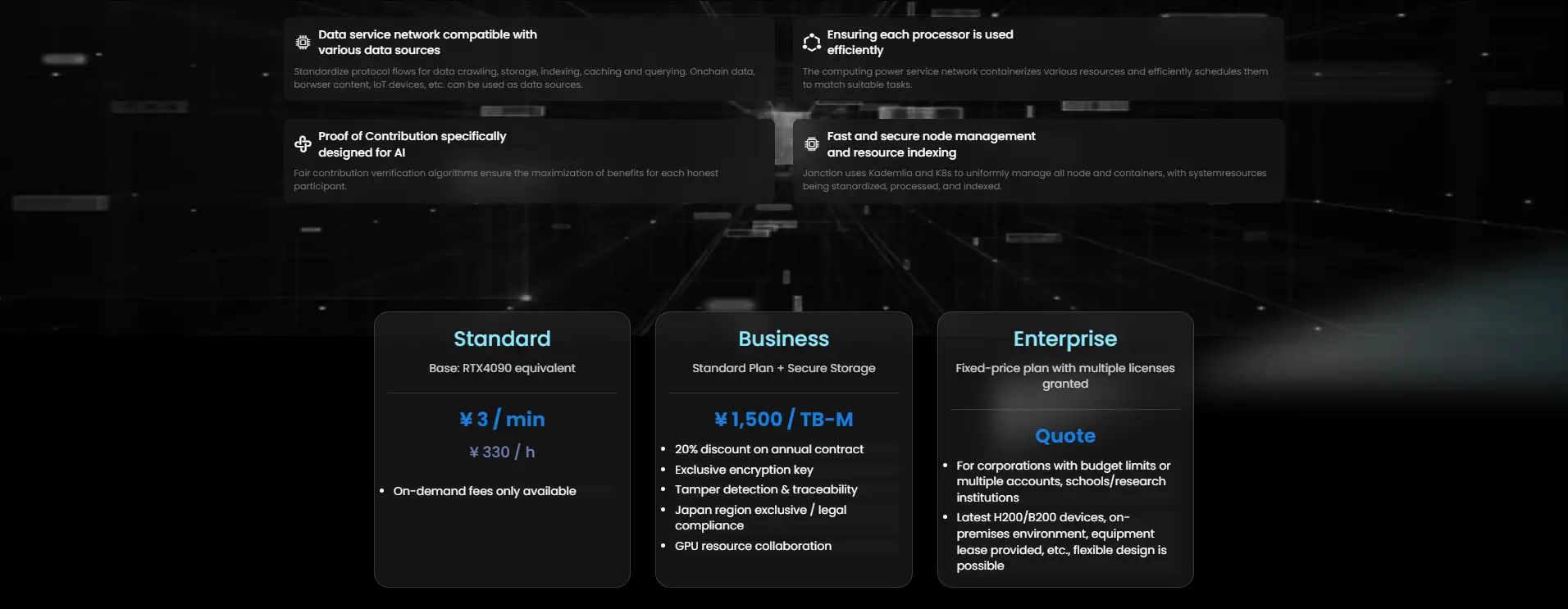
At its core, Janction employs a unique cluster GPU pool architecture to handle scalable parallel workloads. This system supports a wide range of devices—from RTX 4070s to H100s—allowing dynamic task scheduling, GPU allocation, and fault-tolerant load balancing. The platform uses containerization and orchestration frameworks like Kubernetes and Kademlia (K8s) to standardize and index distributed resources for seamless GPU management.
One of Janction’s defining innovations is its Proof of Contribution protocol—an incentive model that verifies and rewards honest participation by measuring actual computational workload. This ensures fair distribution of earnings for GPU providers and supports decentralized AI model training without the need for a centralized authority. The platform also integrates robust privacy and compliance features, including encryption keys, tamper detection, and localized processing to meet legal standards in regions like Japan.
The system architecture enables full-stack AI pipelines, from data acquisition and pre-processing to inference and model fine-tuning. Janction decouples data, compute, and models—allowing these components to interact via smart contracts, ensuring transparency and auditability. A built-in gaming mechanism regulates roles in the network (e.g., data providers, model builders, GPU hosts) through workload correlation functions and VCG pricing to optimize network performance and balance incentives.
Designed for AI developers, research labs, and enterprise clients, Janction offers APIs, SDKs, and microservices for easy model deployment and fine-tuning. Users can host private LLMs, process high-resolution videos, run real-time object detection, or automate AI-based content creation at scale. Unlike centralized AI clouds, Janction provides open access, verifiability, and composable infrastructure with true decentralization.
When compared to competitors like Akash Network, RunPod, or CoreWeave, Janction stands out by deeply integrating AI-specific primitives such as data labeling, verifiable compute, parallel training, and private LLM support—all coordinated on-chain.
Janction provides a comprehensive suite of features designed to make decentralized AI accessible, scalable, and economically viable:
Janction offers a user-friendly onboarding process that allows both individuals and enterprises to begin utilizing distributed GPU resources quickly:
Janction uses a Proof of Contribution mechanism designed specifically for AI workloads. Instead of paying providers only for uptime, Janction measures actual computational work performed using verifiable workload proofs that reflect GPU speed, task complexity, and dataset size. This ensures that high-performance hardware like H100s and 4090s are rewarded relative to their output, while preventing dishonest actors from falsifying results. The system aligns incentives by ensuring every participant receives compensation proportional to their real AI compute contribution.
Unlike generic compute networks, Janction is built as a Layer2 specialized for artificial intelligence. Its architecture integrates data ingestion, GPU scheduling, model execution, and verification directly on-chain, allowing AI tasks to be automated using smart contracts. The platform handles data routing, parallelism, workload partitioning, and cluster management—features that AI workloads require but traditional compute marketplaces typically lack. This makes Janction a purpose-built AI coordination layer rather than a generic GPU rental service.
Janction ensures data privacy and compliance through encrypted storage, tamper‑detection systems, isolated runtime environments, and region-specific deployment options. Business users can access features like exclusive encryption keys, secure storage, and localized compute regions (such as Japan-only nodes) to meet regulatory requirements in industries like healthcare, finance, and government. Sensitive AI workloads—from private LLMs to enterprise analytics—remain secure under Janction’s multi-layer privacy architecture.
The platform separates data, compute, and model layers to create a modular AI pipeline. By decoupling these components, Janction enables tasks like preprocessing, training, and inference to run in independent yet interconnected stages. This design avoids bottlenecks, increases throughput, and makes it easier to scale parallel GPU workloads. Containerized microservices, standardized protocols, and K8s-based scheduling allow AI tasks to flow efficiently through the network, dramatically improving pipeline performance for large‑scale deployments.
Janction uses a combination of containerization, resource indexing, and intelligent scheduling algorithms to match workloads with the most suitable GPUs. The platform’s mixing algorithms allocate idle GPU capacity to appropriate tasks while maintaining isolation, ensuring that no compute resources go to waste. Kademlia‑based node management and Kubernetes orchestration allow resource pools to scale horizontally, supporting multiple users and tasks simultaneously with efficient GPU utilization and minimal conflict.








